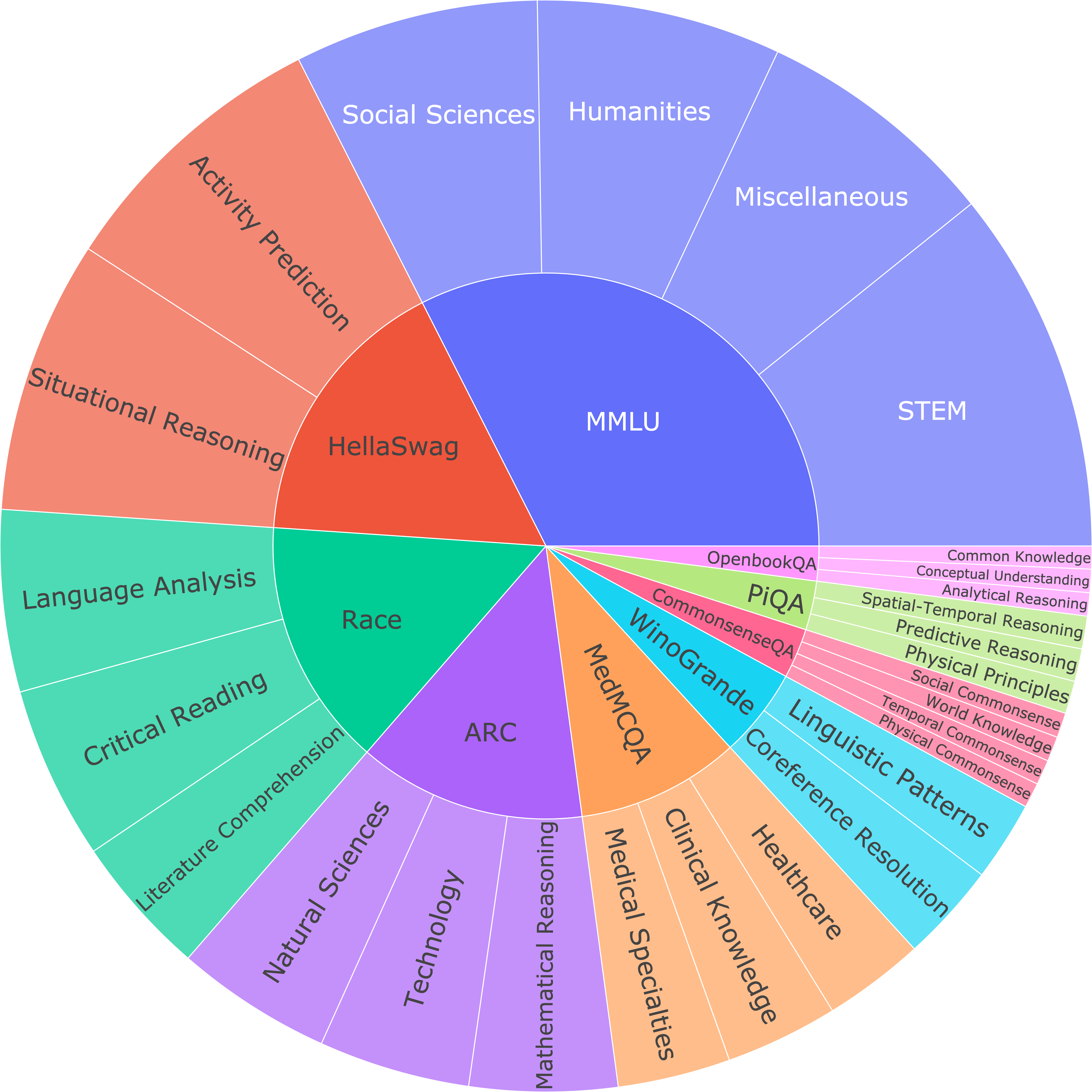
The Open-style Question Benchmark (OSQ-bench) is at the forefront of refining how large language models (LLMs) are evaluated. Moving away from traditional multiple-choice questions (MCQs), OSQ-bench introduces open-style questions to eliminate common biases and enhance the assessment's accuracy. This section details the benchmark's design, showcasing the extensive range and quality of questions it includes and explaining the substantial benefits this format offers. Discover how OSQ-bench is setting new standards in measuring LLMs' true comprehension and reasoning abilities, making it a cornerstone for future advancements in AI evaluation.
| Benchmarks | #Evaluated | #Open-Style | Average Question Length |
|---|---|---|---|
| MMLU | 14,042 | 7,879 | 36.6 |
| ARC | 3,548 | 3,241 | 21.1 |
| MedMCQA | 4,183 | 2,336 | 14.1 |
| Race | 4,934 | 3,528 | 10.0 |
| OpenbookQA | 1,000 | 494 | 10.3 |
| WinoGrande | 1,267 | 1,267 | 19.1 |
| HellaSwag | 10,042 | 3,945 | 40.1 |
| PiQA | 1,838 | 700 | 7.1 |
| Overall | 42,075 | 24,104 | 19.05 |